
Distributed microservice architectures are increasingly common today as engineering teams seek to scale both their applications and headcount. But for all the advantages of microservices, they’re not without tradeoffs. One area of concern is the web of dependencies that’s naturally created as more microservices are built and deployed.
In simple terms, services need to talk to each other, exchanging data as requests are handled by applications. In practice, this is often anything but simple. A single request to a web app might touch 10 different services and include multiple one-to-many relationships. For growing engineering teams, this network of dependencies can quickly become a tangled mess that no one has a complete mental model of. With OpsLevel’s new Service Dependencies capability, you don’t have to worry about siloed knowledge or that one senior architect leaving the company—all your service dependency information can be stored, visualized, and inspected in OpsLevel.
Inspect the details
Building a microservice catalog in OpsLevel that tracks the basic metadata about your services is a key first step in creating an environment where any engineer in your organization is comfortable being on-call. But your services weren’t designed to operate in a vacuum, and so they shouldn’t exist that way in your catalog either. When Service Dependencies are stored in OpsLevel, engineers can start from an individual service detail page and quickly identify any upstream or downstream dependencies the service has.
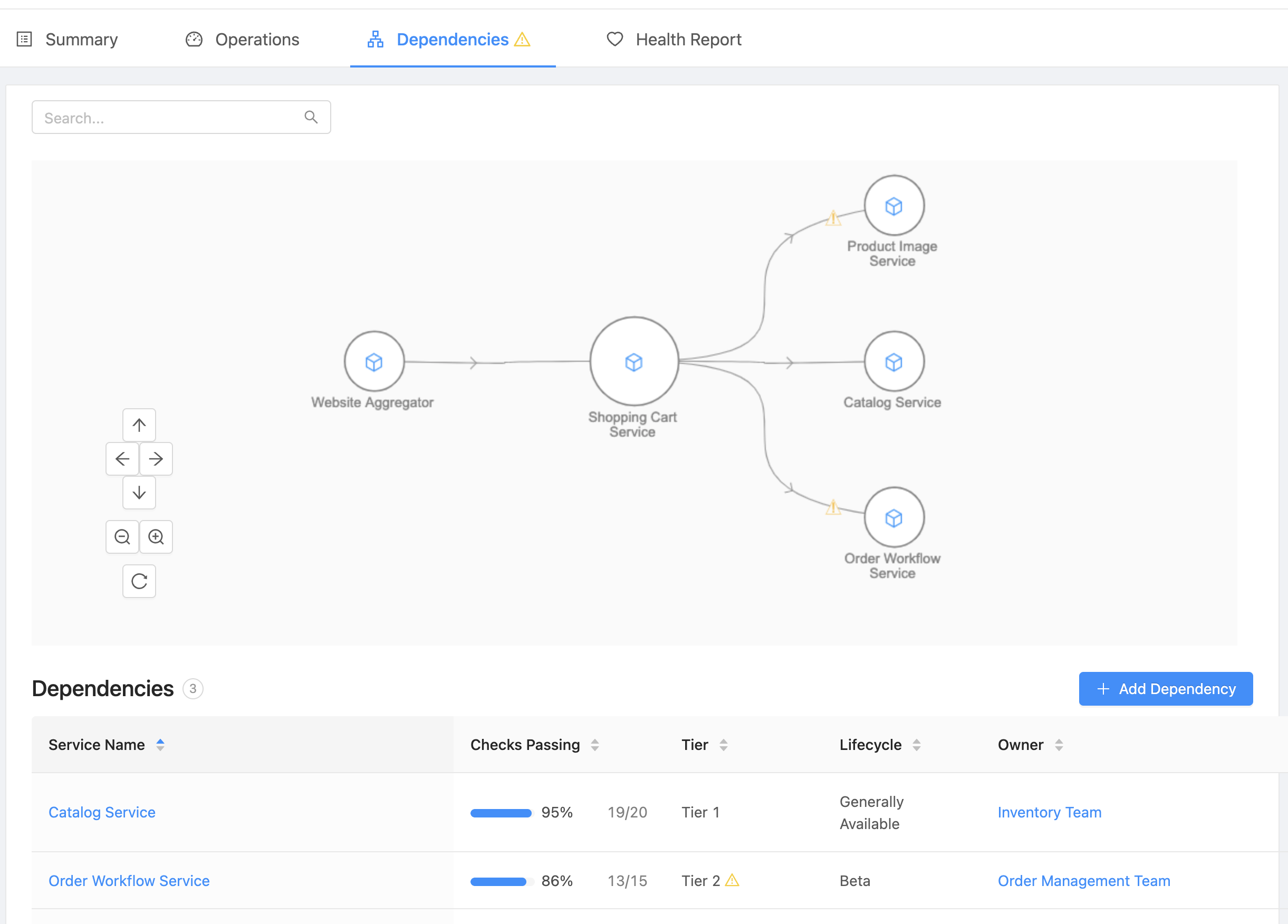
In addition to visualizing those relationships, the Dependencies tab identifies and flags any dependencies on lower tier services, as these may be areas worthy of extra scrutiny. From this screen, it’s also easy to dig into the details and assess the stability of a related service, based on its number of passing checks. Whether engineers are on-call and responding to an incident in the middle of the night or routinely reviewing relationships before deploying a new version of their own service, Service Dependencies is an invaluable lens into your architecture.
What about tracing?
Other solutions, like those from APM vendors Datadog or New Relic, provide service maps that offer some useful insights–answering questions like, which of my services handles the most requests? But they typically fall short on completeness–and can miss the forest for the trees–because their service maps require instrumenting services and collecting traces from them in order to map them. This approach is almost always either cost prohibitive, meaning some service dependencies aren’t tracked, or inefficient, meaning you need to spend time and money integrating every single microservice in your architecture with your APM tool. With OpsLevel, don’t worry about footing the bill for gigabytes or terabytes of traces ingested. Instead, ditch the resource constraints and define your dependencies in any of three different ways:
- directly in our UI
- integrating via our GraphQL API
- with config-as-code in opslevel.yml
The 30,000 foot view
Service Dependencies information is also available top down, so you can inspect your entire architecture from a single, comprehensive graph. This bird’s-eye view can be used for everything from training new engineers on your application architecture to evaluating the cascading impact of deprecating and replacing a particularly troublesome service.
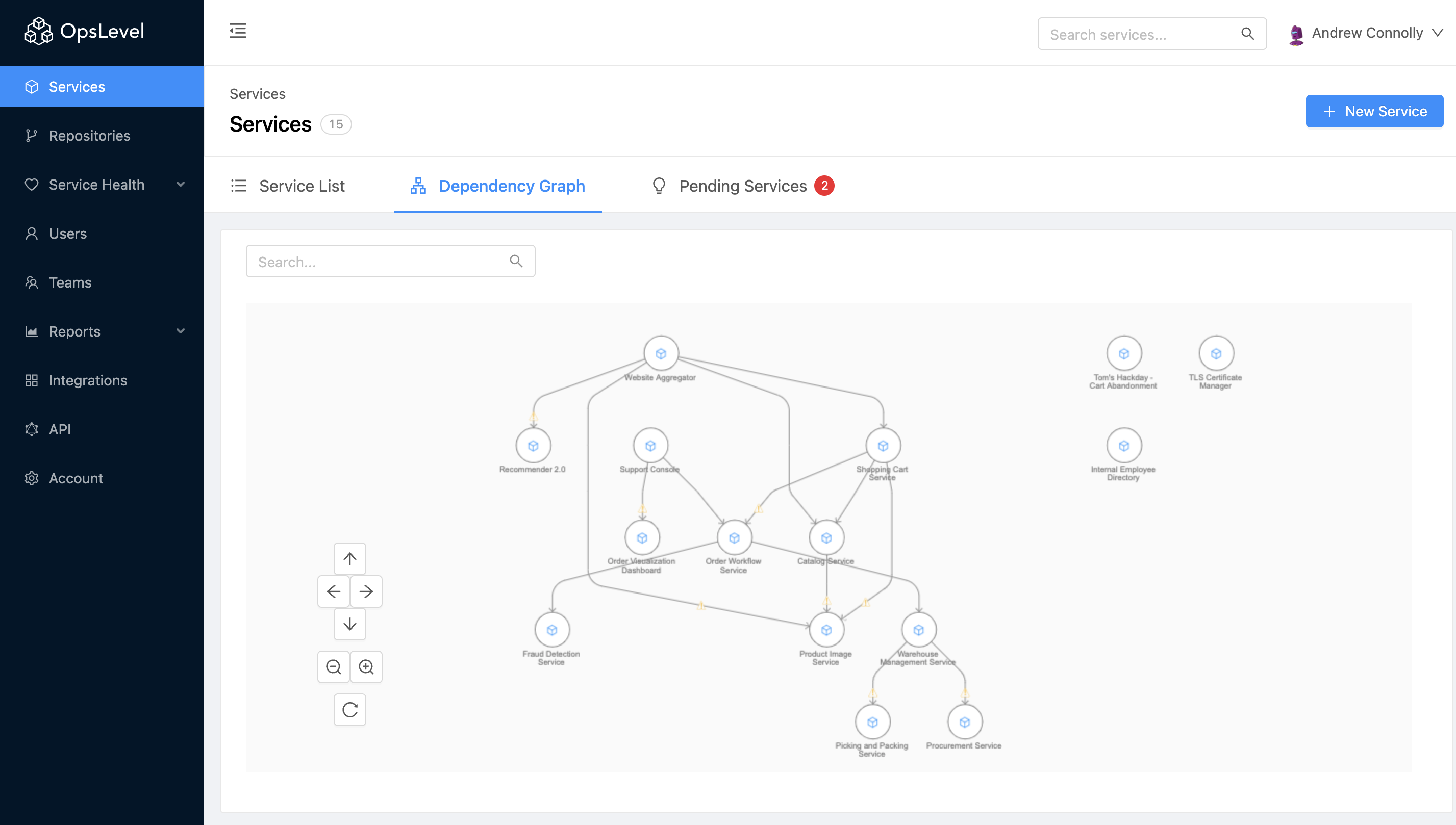
The full Service Dependencies visualization often also has value to stakeholders outside of engineering as well. For example, in order to comply with regulatory frameworks like SOC 2, executives—and auditors—may need a clearly documented digital paper trail laying out which services and teams are responsible for processing sensitive customer data.
If you’re ready to see Service Dependencies in action, request a demo of OpsLevel today.

.webp)

Subscribe
Join our newsletter to stay up to date on features and releases.
By subscribing you agree to with our Privacy Policy and provide consent to receive updates from our company.

