Reliability by default.
Bake automated readiness checks and runbooks into every service so incidents are rarer and fixes are faster.
.avif)


%201.avif)








Readiness enforced, not by email
Define Scorecards that check the basics: SLO present, alert policy linked, on‑call rotation set, runbook attached, dashboard available, error budget policy defined. Every service shows red/yellow/green status so teams know exactly what to fix.
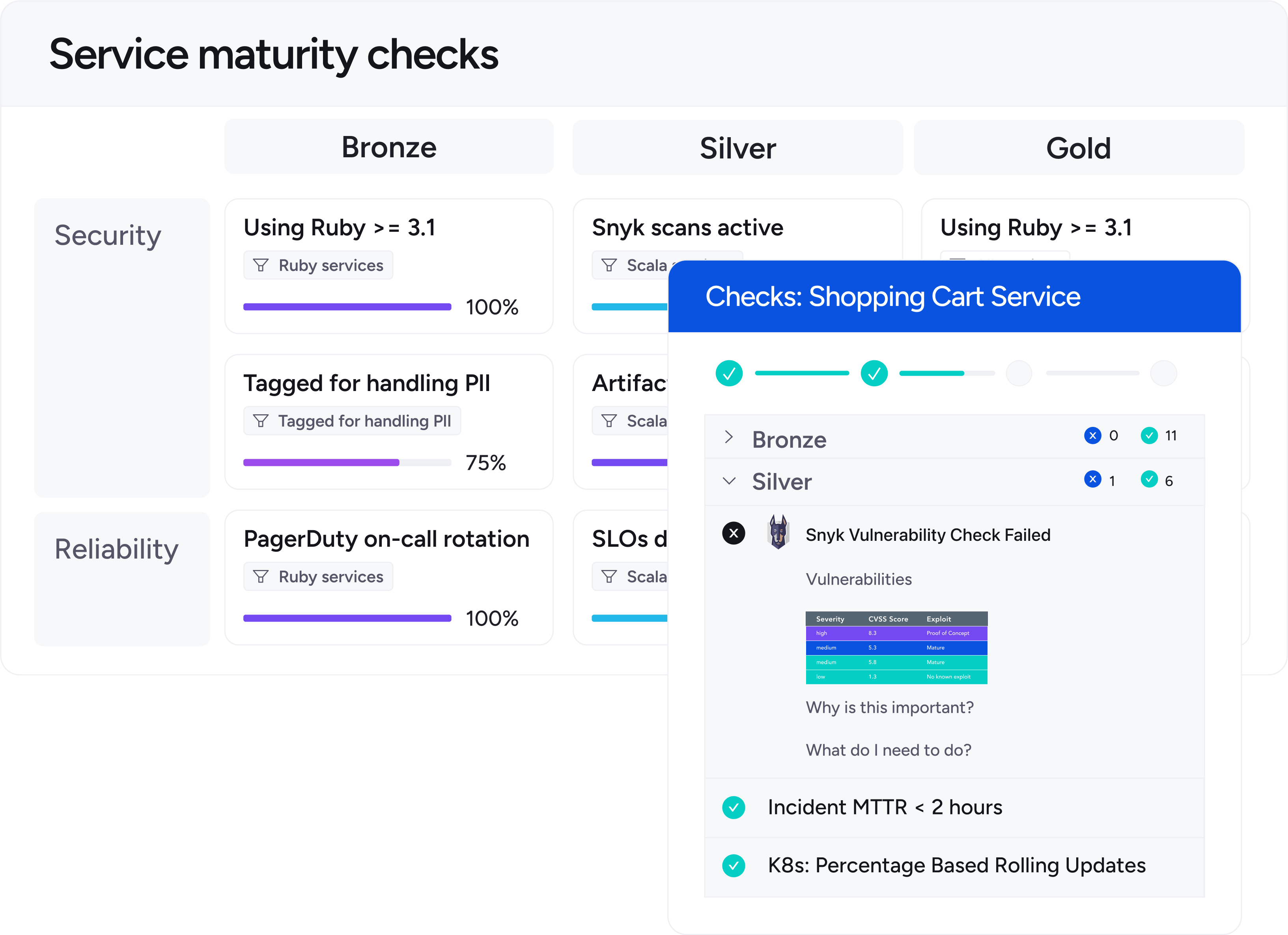

Faster triage, clear ownership
Each service page shows owner, runbooks, dependencies, dashboards, recent deploys, and links. On‑call starts with context, not a scavenger hunt.
Safer changes when things get spicy
Use Actions for deploy freeze/unfreeze, rollback, canary promote/abort, and incident declaration—right from the portal. Send notifications to PagerDuty/Slack so the right people know, instantly.
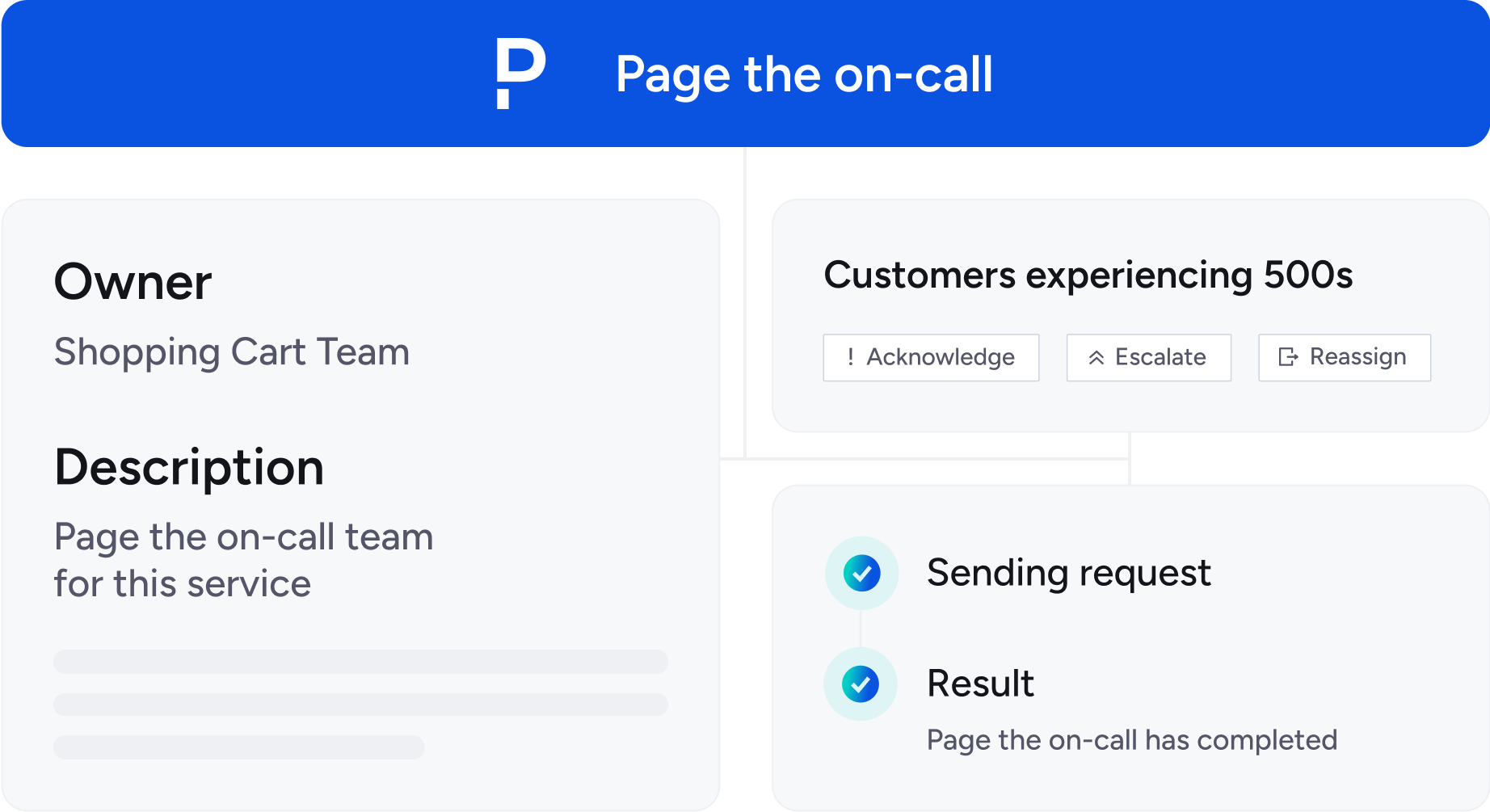

Prove that reliability improves over time
See readiness coverage over time, track gaps closed by team, and correlate change safety with outcomes you already track (MTTR, incident rate, change failure rate).
Tagline Text
How it works
1.
Connect
Connect Git, CI/CD, incident tooling, observability, and chat. The catalog assembles ownership, links, and dependencies.
Outcome: a reliable system of record for “what is this service and who owns it?”
2.
Codify readiness
Publish your Reliability Rubric and attach Scorecards across services: SLO present, alerting configured, runbook linked, dashboard available, on‑call rotation set.
Outcome: readiness is visible and measurable across the estate.
3.
Scale & measure
Publish your Reliability Rubric and attach Scorecards across services: SLO present, alerting configured, runbook linked, dashboard available, on‑call rotation set.
Outcome: readiness is visible and measurable across the estate.
Start today
Engineering is hard work. Your developer portal doesn’t need to be.


