
Today, Kubernetes is the de facto standard for container orchestration, running in approximately half of all containerized environments. Platform and infrastructure teams of all shapes and sizes are accustomed to operating Kubernetes in order to run their organizations’ microservices (and applications) at any scale.
This makes Kubernetes a natural source of valuable service metadata. With OpsLevel’s new Kubernetes Sync, integrating your Kubernetes cluster with OpsLevel has never been easier. Whether you are:
- bootstrapping your OpsLevel account for the first time
- reconciling changes between your Kubernetes cluster and your service catalog
- using the Kubernetes Sync in conjunction with OpsLevel Checks to drive best practices across your cluster
our kubectl extension can streamline and automate your workflows–so your microservice catalog is tracking and measuring what actually exists in your production clusters.
Getting Started
The new integration supports a wide variety of use cases and workflows. First and foremost, it’s designed to provide another route for importing crucial service metadata into OpsLevel. Especially for larger architectures that may have hundreds of services, we want to provide the best tools for quickly and efficiently building your service catalog.
To get started, the first step is installing the kubectl extension. Installation instructions are available in our GitHub repo.
Once installed, our Kubernetes Sync leverages jq to slice, dice, and map all relevant service metadata from Kubernetes into OpsLevel. Our extension enables easy filtering, so you can exclude Kubernetes resources that may not be relevant for OpsLevel, such as resources in the kube-system namespace. All core OpsLevel fields are covered by the sync, including service aliases, tags, tier, tools, and team/owner. You can learn more about the full configuration options in our documentation.
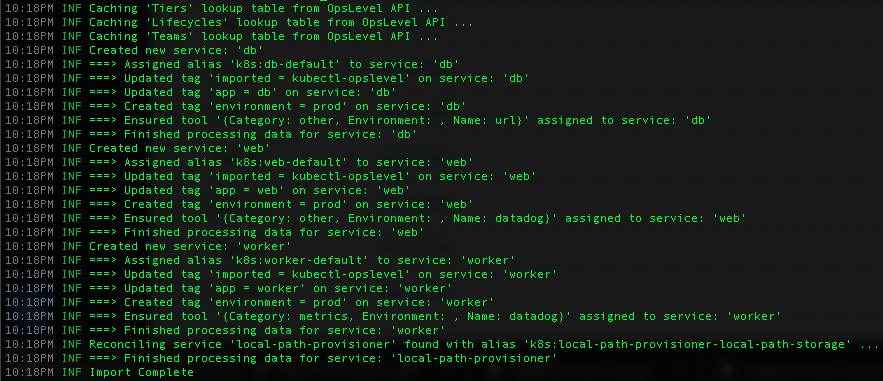
Staying Current
In addition to helping you populate your service catalog from scratch, with our helm chart, the integration can run within your Kubernetes cluster, ensuring data is regularly synced between your cluster and OpsLevel. Scheduled syncs keep your service catalog up to date, so any new service running in your cluster will be automatically recognized and imported by OpsLevel.
Automated syncs also allow data from your Kubernetes cluster to be treated as a first class data source within OpsLevel, just as code repositories or deployment histories already are.

Building for Consistency and Reliability
Kubernetes as a data source means it’s now straight-forward to monitor and enforce your organization’s preferred Kubernetes best practices, and incorporate those infrastructure attributes into your broader production readiness checklists.
For example, at one OpsLevel enterprise customer, the infrastructure engineering team wanted to drive and report on a migration from one container image registry to another. Using OpsLevel to collect (Kubernetes Sync), organize (Rubrics), and report on (Check Reports) all the necessary data makes these compliance or standardization projects easier–and makes engineering managers happy. But, the bigger win actually comes from the second order effects–the time and money saved.
For this customer, accelerating their consolidation onto a single container registry meant saving money twice–paying only one registry provider and then reducing their cloud security bill since they only needed to scan one registry instead of two.
Increased visibility into your Kubernetes configuration can also be a benefit to service reliability. In another example, a customer used OpsLevel’s Kubernetes integration, in conjunction with Checks, to validate that application teams were shifting to a new ingress controller architecture based on isolation instead of resource sharing among teams.
A similar approach was also used to confirm their Kubernetes deployments were using a percentage-based rolling update strategy, in order to better handle scaling and avoid hours-long deployments.
These examples are just scratching the surface; Kubernetes’ API contains a wealth of actionable information that can now be easily integrated into OpsLevel to help you run Kubernetes in production more resiliently, efficiently, and securely. If you’re ready to see it in action, request your OpsLevel demo today.

.webp)

Subscribe
Join our newsletter to stay up to date on features and releases.
By subscribing you agree to with our Privacy Policy and provide consent to receive updates from our company.

