

More software, more problems?
Software is eating the world and that means more people and teams are developing software. To stay current and competitive, modern organizations are scaling their software engineering teams. And to scale effectively means adopting a microservices-based architecture, so development teams can remain small, stay agile, and operate independently of each other.
Now you’re scaling and developing software faster. Across the organization, you’re shipping code multiple times an hour, instead of once a month. But your operations team can’t scale at the same pace. To adapt, you move to a DevOps culture and dev teams both build and operate systems themselves.
But your dev teams already have a lot on their plate, and don’t have extensive operational experience. They’re not reliability, observability, or security experts. Issues are occurring more often.
Devs now have responsibility for critical user-facing systems, in situations where every minute counts and lost trust—or revenue—can be lost quickly. Stressful.
And what if these devs didn’t actually build these systems? Maybe they’re new to the team, or ownership has been shifted around after a re-org. Stress increases and incidents take even longer to resolve.
And with decentralized operations, after one team learns from an incident, it doesn’t mean the rest of your dev teams will. So the same types of mistakes are being made again and again.
The end result? Decreasing reliability as the number of engineers & microservices grow.
But it doesn’t have to be this way. With the right context, anyone in your engineering org can quickly and effectively respond to incidents.
Increasing software reliability with a microservice catalog
Let’s first look at how a microservice catalog can bring structure and clarity to your pursuit of five nines.

Set your standards
A microservice catalog can provide specific, actionable production-readiness guidelines to your developers. Then it continuously monitors them with automated checks. These guidelines can be crafted to cover every aspect of service quality, including security, scalability, and resiliency. Checks are dynamically applied to relevant services based on their tier or lifecycle stage. With the right reminders and guardrails in place, engineers can comfortably operate existing microservices and spin up new ones with best practices built-in.
For example, you could easily measure and enforce that every generally-available Tier-1 production microservice needs to:
- Have an owner
- Have a PagerDuty rotation
- Use a version of Rust that is greater or equal to 1.50.0
- Have observability tools in place: logging, metrics, and tracing
- Have at least 1 defined SLI/SLO
- Be running on Kubernetes
- Have a runbook for common failure modes
- Have zero critical security issues identified by your SAST
- Have tested their disaster recovery plan in the last 6 months
In addition to increasing overall reliability, standards free your engineers from complexity by reducing cognitive load. They know what’s expected, consistency across services comes easily, and they can focus on shipping excellent products and end-user experiences.

Track and measure your progress
Of course, setting these guidelines for tens or hundreds of microservices won’t have an impact overnight. But a microservice catalog also helps you continuously evaluate your services against these guidelines and share progress with your stakeholders. Quickly view reports showing which teams and services are on the golden path, and which ones need additional attention.
Need to migrate to Kubernetes or upgrade all your Go microservices to the latest version? Get rid of your spreadsheet and implement a microservice catalog to help you get it done faster.
Respond to incidents faster
Despite the best laid plans, incidents will happen. No matter how exacting your proactive guidelines are, teams need to be equipped to react effectively–especially when paged in the middle of the night. Again, a microservice catalog can help. It won’t replace your existing tools like PagerDuty or Datadog, but instead complement them by providing complete context and connecting all the dots.
Centralized information
With a microservice catalog, you can access all the critical information necessary to resolve an outage. There’s no need to dig through ten different outdated wikis or spreadsheets to understand what a service does, who the owner is, and where the relevant runbooks and observability data resides. Don’t lose precious minutes during an incident because an on-call engineer has to verify whether the impacted services are still monitored in New Relic or Datadog. And which index are the logs in?
Instead, track all the metadata about your services in one single place so you don’t discover an orphaned or poorly documented service when you can least afford it–during a sev1 incident.

Integrated into your workflow
A microservice catalog doesn’t have to be yet another complex tool that engineers need to learn and master.
A microservice catalog can be integrated into standard ChatOps workflows. Directly integrate your data in your team’s collaboration platform. Easily search for services and find all the essential operational data in Slack right when an incident’s called. Remediate incidents faster when all the appropriate data is at your fingertips.
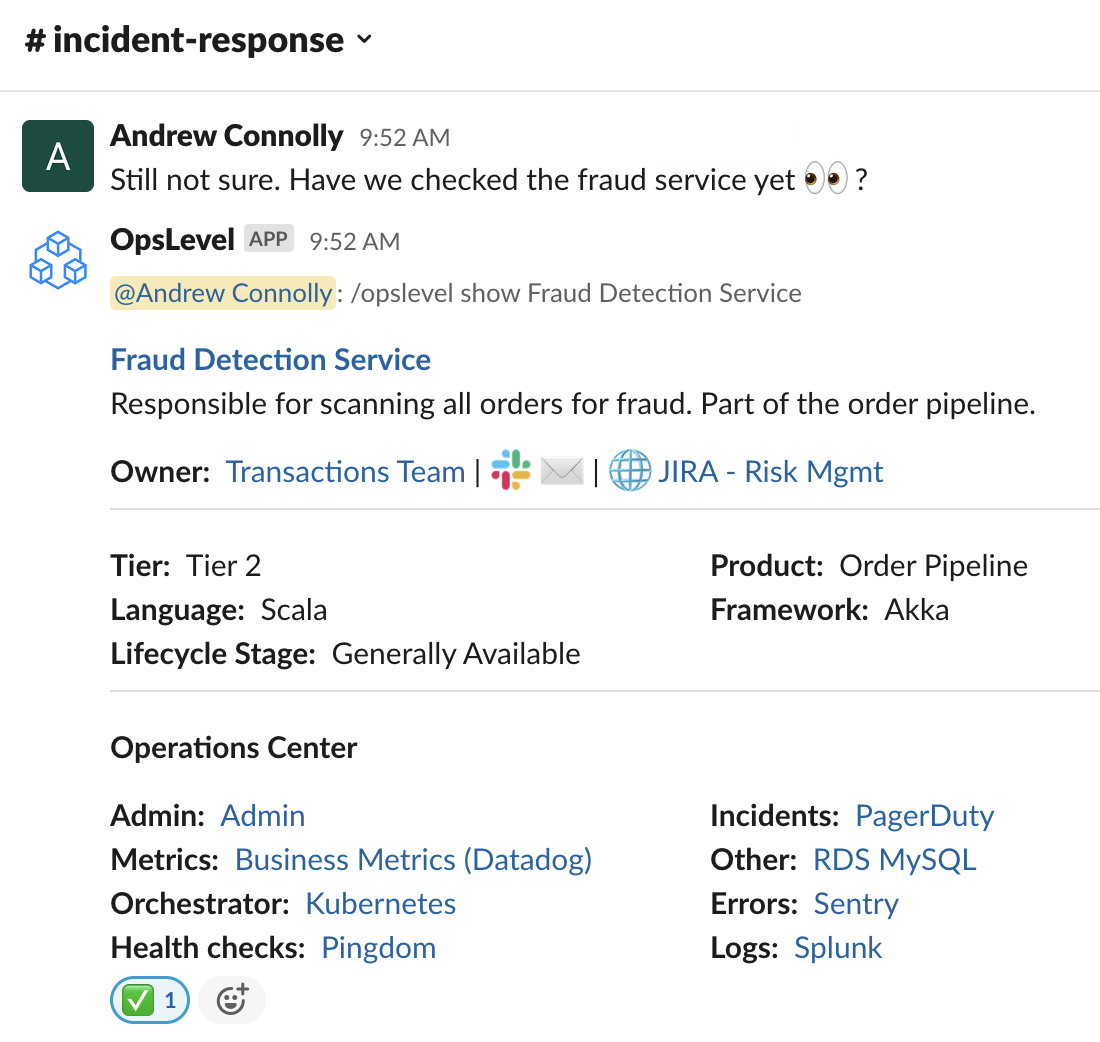
Implementing a microservice catalog
Microservices should be building blocks, not stumbling blocks. If you agree and want to learn more, schedule your demo of OpsLevel today.
We’ll show you:
- how a microservice catalog can help you build more reliable software and resolve incidents faster
- why forward-thinking engineering teams at Zapier, Segment, and Convoy love using OpsLevel every day.
Questions? Get in touch today to get answers and schedule your OpsLevel demo.
John Laban is a co-founder of OpsLevel and previously was PagerDuty’s first engineer. He’s spent the last decade scaling engineering teams and helping them transition to DevOps.

.webp)

Subscribe
Join our newsletter to stay up to date on features and releases.
By subscribing you agree to with our Privacy Policy and provide consent to receive updates from our company.

