The fastest way to catalog your software
With AI and automation on your side, you can build and maintain a complete catalog faster than ever.
With AI and automation on your side, you can build and maintain a complete catalog faster than ever.

Automatically detect services from your tech stack, trace ownership back to teams, and map relationships like systems and domains, to get a reflection of your production environment that your team can trust.
Cataloging metadata is important, but tedious. Our AI Assistant generates inferred service descriptions based on your repository contents to help you complete your catalog faster—and without the hassle.

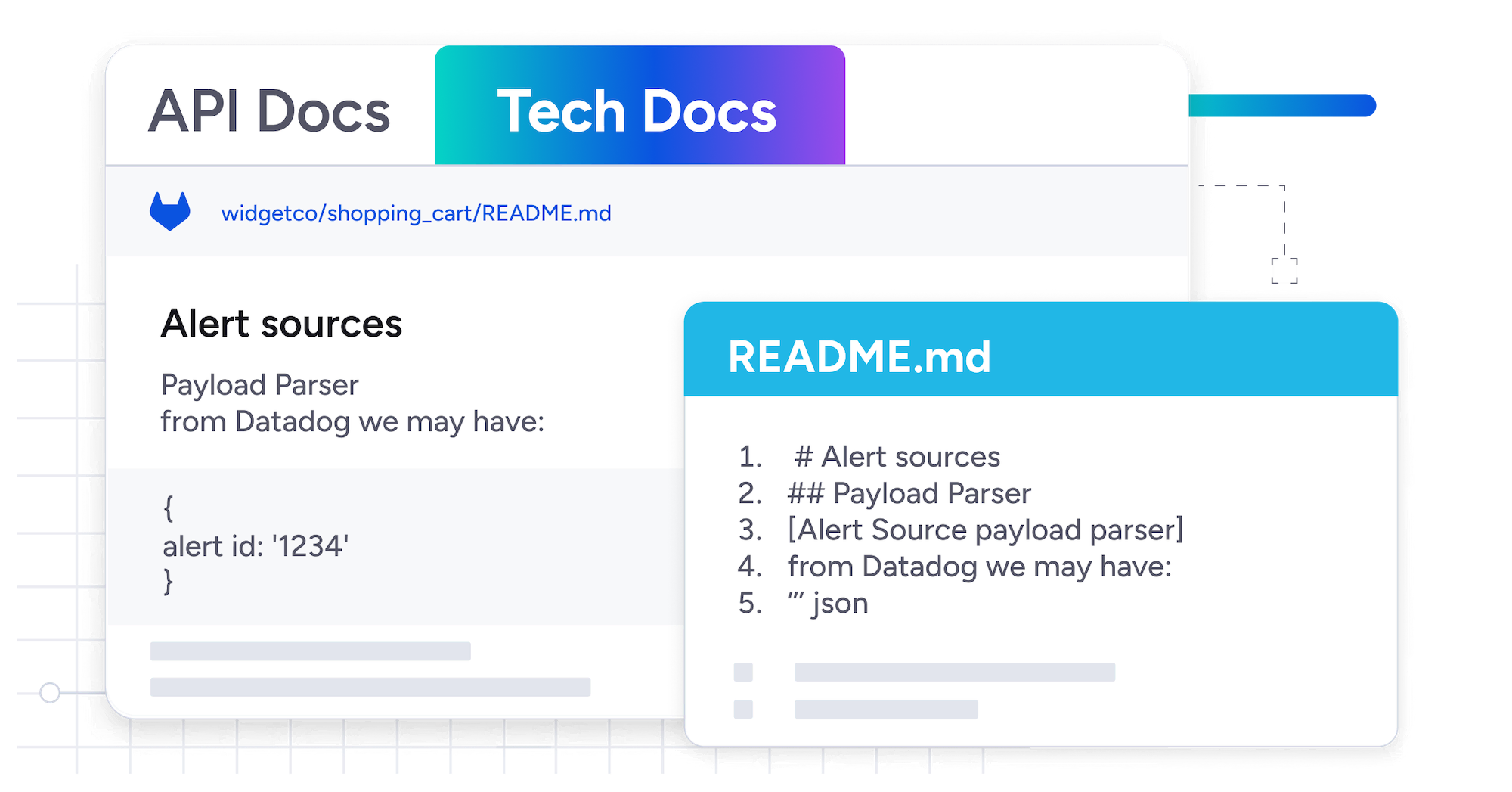
Docs-as-code on your to-do list? We automatically surface markdown files that live in your repo for easy and instant access giving your team the context they need, when they need it.
Get a custom plan to implement an internal developer portal for your team.

OpsLevel’s AI assistance generates automated service descriptions using the contents of your repository files and data from across your services architecture.
Many services are missing descriptions in OpsLevel. This information offers critical context for broader engineering teams, but motivating service owners to keep them updated is a chore. With AI-generated service descriptions you get meaningful context added to your catalog automatically, without the hassle.
The feature is currently disabled by default on all existing customer accounts. It will be enabled by default for new accounts, including free trials, as of Thursday, October 12, 2023. Access to the feature can be turned on (or off) at any time through a request to your OpsLevel Customer Success team.
In addition to OpsLevel’s typical code-scanning functionality, we’re using a large-language model hosted by OpenAI. If this feature is enabled, your repository contents could be submitted to the OpenAI API for analysis. OpenAI will read any repository content; it prefers documentation, but it will also read code.
We then leverage OpenAI’s GPT 3.5, 3.5-turbo, and 4 to generate proposed service descriptions for any catalog entity missing one, based on the context it’s found in your linked repositories.
We have an agreement with OpenAI that none of your code is stored at rest permanently. Per OpenAI API Data Usage Policies, OpenAI will not use your data to train their models.
The agent transiently scans your documentation and code and uses it to make an inference about what a service’s description should be.
Similar to our repo checks, after computing a result, the original input code and documentation is eventually discarded.
We care deeply about who has access to your code and where it is stored. We handle your data in accordance with our Privacy Policy and data protection regulations. As always, our complete subprocessor list is available on our trust portal.

